8 minutes
DINO - Emerging properties in self-supervised vision transformers
Today’s paper: Emerging properties in self-supervised vision transformers by Mathilde Caron et al.
Let’s get the dinosaur out of the room: the name DINO refers to self-distillation with no labels.
The self-distillation part refers to self-supervised learning in a student-teacher setup as is often seen for distillation. However, the catch is that in contrast to normal distillation setups where a previously trained teacher network is training a student network, here they work without labels and without pre-training the teacher.
Despite not using labels, the representations which are learned look impressive and can be used to learn many downstream tasks very efficiently.
As a primer, this is how the representations look like after training - almost like semantic segmentation maps:

Figure 1 from the paper: self-attention of the transformer heads of the last layer. Objects can be clearly identified although the network was trained without labels and without supervision.
Basic setup of DINO
As already hinted at, two networks are used here - one student network and one teacher network. They use exactly the same architecture and are initialized with the same weights, so the teacher is not pre-trained or anything like that. Instead, only the student is trained with stochastic gradient descent and the teacher is only updated from the student using an exponential moving average (ema) of both the weights of the teacher and the student. To only update the student, a stop-gradient (sg) is applied at the teacher.
The networks output a K-dimensional feature vector which becomes normalized by a temperature softmax over the feature dimension.
In contrast to the student, the K-dimensional feature vector of the teacher becomes centered and the temperature is smaller, so the output is more extreme which is referred to as sharpening here.
After both softmaxes, their similarity is determined by a cross-entropy loss, i.e. we want the student to predict similar to the teacher.
The easiest solution to solve this would be to predict the same representation for every image in which case the loss would be zero. Of course, we want to prevent this as having the same representation for every image would be quite pointless. As we will see later, there are two important parts to prevent this easy collapsing solution: 1) the exponential moving average and 2) the centering and sharpening of the teacher.
Here is a graphical illustration of the setup from the paper:
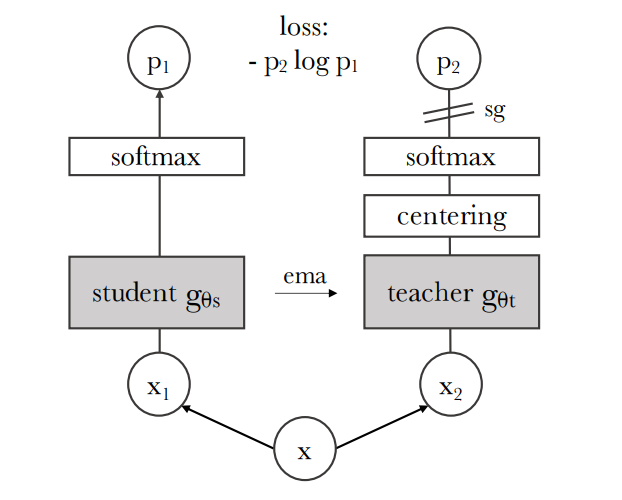
Visual illustration of the method - taken from Figure2 of the paper
It sounds quite odd, right? We don’t use labels and the networks influence each other (the student is trained and updates the teacher using the ema), so how come useful representations come out in the end?
We need to take a look at several parts in more detail to understand what’s going on. First of all: augmentations.
Image augmentations - an important ingredient
Augmentations play a key role in this setup as there is quite a specific way of how they are used especially when it comes to image crops.
There are two different crops the paper refers to:
- Global crops are crops which cover at least 50% of the image, so they contain most of the original image information.
- Local crops are crops which cover less than 50% of the image, so they are rather local features; they are also smaller in size than the global crops.
The catch is this: the teacher network is only fed with global crops, so it can represent the general concept of the image while the student is fed with both global and local crops. With this setup and the cross-entropy loss forcing the student to have similar predictions as the teacher, we push the network to learn the parts of the local crops which are helpful for the overall, global representation.
Avoiding the collapse: centering and sharpening
In addition to using the ema update from student to teacher, the paper explains that centering and sharpening are used to avoid the trivial solution collapse.
There are two trivial solutions which are easy to see:
- Output uniform representations for each example, i.e. activate each feature with the same strength.
- Let one feature dominate, so maximally output that feature and set all other features to zero.
Centering is keeping a running average of all the representations which the teacher computes. The running average is subtracted from the currently output representations before applying the softmax. The idea is to avoid that single feature dimensions become too dominant and rule over the others. So essentially, it tries to make the distribution more uniform and avoids trivial solution 2).
In contrast, sharpening does the opposite - it makes sure that the softmax outputs have a peaked distribution. This is achieved by using a lower temperature parameter for the softmax step for the teacher than for the student. This also makes a lot of sense if you think about the global / local crop augmentation. The teacher has the global information and by using sharpening is forced to commit more to a peak for the target class. The trick is that we train without classes, so the target class needs to be learned / inferred from the data.
Essentially, the softmax operation creates a distribution over helper classes of dimensionality K and we first make sure that the teacher doesn’t collapse by predicting always the same class using centering, but at the same time force it to commit to some class more clearly using sharpening.
This way, we prevent collapsing strategies, but at the same time also have a better learning signal from teacher to student.
The paper also provides a couple of experiments and illustrations relating the centering / sharpening to the collapse avoidance that I won’t cover in more depth here now.
Quick look at ablations
It’s always quite interesting to see which parts of new methods actually contribute the most and fortunately, they provide several ablations here.
We can summarize those as:
- When not using the ema update, the training doesn’t converge, so it’s an essential part.
- Using Sinkhorn-Knopp updates (kind of like ensemble learning) can be used as an alternative to ema, but it doesn’t add to it.
- The multi-crop augmentations are essential to learn great representations, but even without them it works to some extent.
- Cross-entropy loss works much better than mean squared error in this setup.
Vision Transformer vs. ResNet / convolutional feature encoder
The proposed method can be used with a convolutional ResNet encoder as well as with a vision transformer. However, throughout the paper, the authors note that the representations using the Vision Transformer turn out to quite a bit better.
The vision transformer is used here by splitting the input image into patches of size 8x8 or 16x16 pixels and unrolling them into a vector which is fed to an embedding layer to obtain an embedding for each patch. The transformer is then applied on this sequence of embeddings as is the case in the language domain with words as well.
The visualization of the attention heads gives something like a segmentation map of objects which is super interesting given that it learned these concepts by itself without labels and supervision.
When using the ResNet encoder, you can also see that it can find the relevant parts, so the training setup itself is helpful to obtain so, but you can see many more artefacts.
Moreover, when using the vision transformer, you can apply a k nearest neighbor classifier on the output features and it’s almost as good as training a linear classifier on the features.
Here is a performance comparison where this effect is notable:
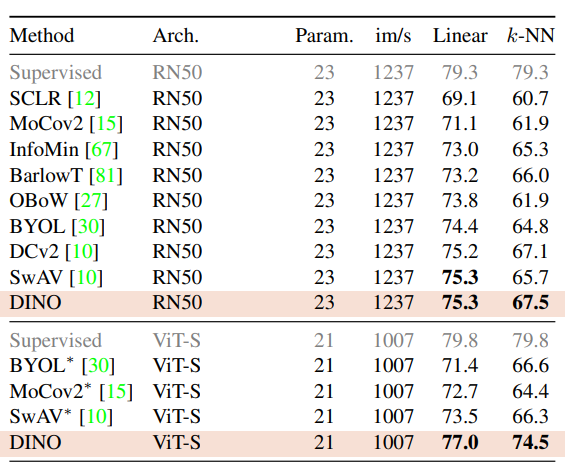
Excerpt from Table 2 of the paper: performance comparison of different models. DINO performs much better with ViT-S as the backbone than with ResNet-50, especially for k-NN.
Summary
This was quite an interesting read with cool ideas and very interesting results. The student-teacher setup is guided by local-global augmentations and exponential moving average updates of the weights. To prevent trivial solution collapse, centering (push the representations to be more uniform) and sharpening (push the final distribution to be more peaked / extreme) are used.
The emerging properties which have been identified to come up especially when using a vision transformer are:
- The attention features contain semantic segmentation like properties without being trained in this way (no labels, no supervision)
- The features are also very good k-NN classifiers and can essentially do 0-shot learning - predicting the classes of images without being trained with any explicit examples of that class
The question remains why these properties emerge and there are two factors that I can see contributing here: a) the setup of the global-local augmentations together with centering and sharpening and applying a softmax step are kind of pushing the network to predict classes. They are not labeled, but they are setup to predict a class distribution over K features and b) the ImageNet data which this is trained on contains in most images a central object which the network needs to focus on to get the global-local matching right.
I speculate that this works better with the transformer approach as it can naturally cover a larger visual receptive field with it’s attention maps, so it might be easier to pick up this local-global information and represent that internally while the convolutional approach is more constrained with the bias of locality of it’s kernels.
Reference
- Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, Armand Joulin: Emerging Properties in Self-Supervised Vision Transformers
machinelearning deeplearning paper transformer computervision
Machine Learning Deep Learning Papers
1577 Words
March 13, 2022