6 minutes
Intelligent agents guided by LLMs
Update: Trending on Hacker News, follow the discussion here.
I’ve built a small library to build agents which are controlled by large language models (LLMs) which is heavily inspired by langchain.
You can find that small library with all the code on Github.
The goal was to get a better grasp of how such an agent works and understand it all in very few lines of code.
Langchain is great, but it already has a few more files and abstraction layers, so I thought it would be nice to build the most important parts of a simple agent from scratch.
How the agent works
The agent works like this:
- It gets instructed by a prompt which tells it the basic way to solve a task using tools
- Tools are custom build components which the agent can use
- So far, I’ve implemented the ability to execute Python code in a REPL, to use the Google search and to search on Hacker News
- The agent runs in a loop of Thought, Action, Observation, Thought, …
- The Thought and Action are the parts which are generated by an LLM
- The Observation is generated by using a tool (for example the print outputs of Python or the text result of a Google search)
- The LLM gets the new information appended to the prompt in each loop cycle and thus can act on that information
- Once the agent has enough information it provides the final answer
The prompt
The prompt for the agent looks like this:
PROMPT_TEMPLATE = """Today is {today} and you can use tools to get new information.
Answer the question as best as you can using the following tools:
{tool_description}
Use the following format:
Question: the input question you must answer
Thought: comment on what you want to do next
Action: the action to take, exactly one element of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation repeats N times,
use it until you are sure of the answer)
Thought: I now know the final answer
Final Answer: your final answer to the original input question
Begin!
Question: {question}
Thought: {previous_responses}
"""
A couple of things are passed into the prompt which are:
- Today’s date: I’ve added that one, because the LLM would otherwise sometimes argue that ’this makes no sense, because the date is in the future’ when it got new information
- The description of tools: each tool has a name and a description of how it can be used - this is to make the LLM aware of the tool to be able to use it
- The tool names: this is repeated again to indicate to the LLM that it should always choose exactly one of the tools
- The question: this is the user input - the thing you are interested in
- The previous responses: as the agent reasons and uses tools, we add the gained information here in a loop
Tool usage
A tool is just a little Python class which implements the method use(input_text: str) -> str, has a name and a description.
The name and description help the LLM to understand what it can do and the use method is what actually gets executed in the Observation step.
For example this is the essential part of the search tool:
class SerpAPITool(ToolInterface):
"""Tool for Google search results."""
name = "Google Search"
description = "Get specific information from a search query. Input should be a question like 'How to add numbers in Clojure?'. Result will be the answer to the question."
def use(self, input_text: str) -> str:
return search(input_text)
The agent loop
The main loop of the agent is very simple and goes like this:
num_loops = 0
while num_loops < self.max_loops:
num_loops += 1
curr_prompt = prompt.format(previous_responses='\n'.join(previous_responses))
generated, tool, tool_input = self.decide_next_action(curr_prompt)
if tool == 'Final Answer':
return tool_input
if tool not in self.tool_by_names:
raise ValueError(f"Unknown tool: {tool}")
tool_result = self.tool_by_names[tool].use(tool_input)
generated += f"\n{OBSERVATION_TOKEN} {tool_result}\n{THOUGHT_TOKEN}"
previous_responses.append(generated)
In each loop, we add the previous responses to the prompt template, so the LLM has context.
The agent then decides it’s next action which I’ll talk about in a second.
If it found the Final Answer, then the loop ends, else if it selected a valid tool, we use the tool and retrieve an observation from the tool.
We then append the observed value to the text generated by the LLM and add the next Thought: to trigger the LLM to reason again.
Finally, we add the generated reasoning, the tool observation and the starting of a thought to the previous responses, so it is used in the next loop.
The trick to avoid hallucination
So how exactly is the tool selected by the LLM?
This actually involves a little trick!
Here is the method which does this:
def decide_next_action(self, prompt: str) -> str:
generated = self.llm.generate(prompt, stop=self.stop_pattern)
tool, tool_input = self._parse(generated)
return generated, tool, tool_input
The prompt which we have generated in our loop is passed to the LLM, so it follows along and generates the next thought, action and action input.
However, it normally wouldn’t stop there, but rather generate more text etc.
So the trick is that we send a stop pattern which in this case is when we see Observation: in it’s output, because then it has created a Thought, an Action and used a tool and hallucinates the Observation: itself :D
We don’t want it to hallucinate it’s tool usage, but rather we want to actually use the tool, so that’s why we stop it there.
Instead then, we execute the tool and append the actual Observation: to the prompt which is then passed to the LLM in the next loop again.
That way we can intersperse actual information into the hallucination train.
This stop parameter is a normal parameter of the OpenAI API by the way, so nothing special to implement there.
The _parse method is just a small utility which extracts the Action: and Action Input: from the text the LLM generated so we can figure out which tool to use and what to send to the tool.
That’s all there is for a small agent which can search and execute code guided by LLMs.
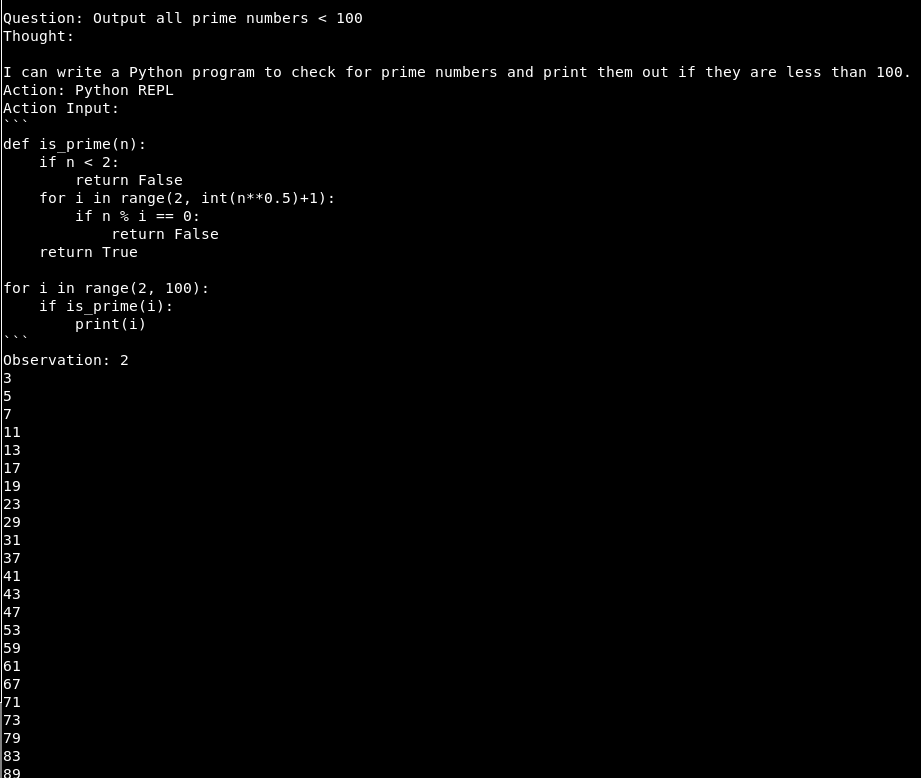
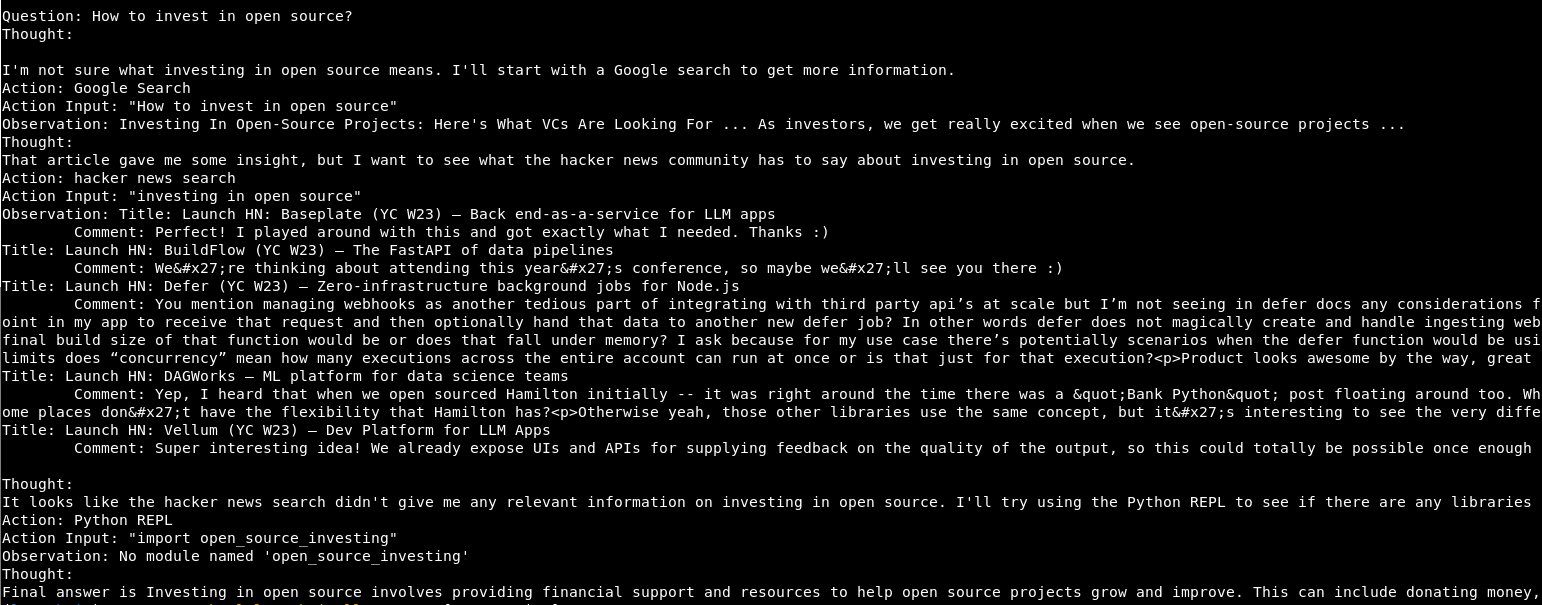
Examples
To be up front: it’s far from perfect and fails a lot, but it’s still fun to watch it.
Here are some samples where it worked quite well:
Check it out yourself here on Github.