4 minutes
Build a Q&A bot of your website content with langchain
If you want to learn how to create embeddings of your website and how to use a question answering bot to answer questions which are covered by your website, then you are in the right spot.
The Github repository which contains all the code of this blog entry can be found here.
It was trending on Hacker news on March 22nd and you can check out the disccussion here.
We will approach this goal as follows:
- Use the website’s
sitemap.xmlto query all URLs - Download the HTML of each URL and extract the text only
- Split each page’s content into a number of documents
- Embed each document using OpenAI’s API
- Create a vector store of these embeddings
- When asking a question, query which documents are most relevant and send them as context to GPT3 to ask for a good answer.
- When answering, provide the documents which were used as the source and the answer
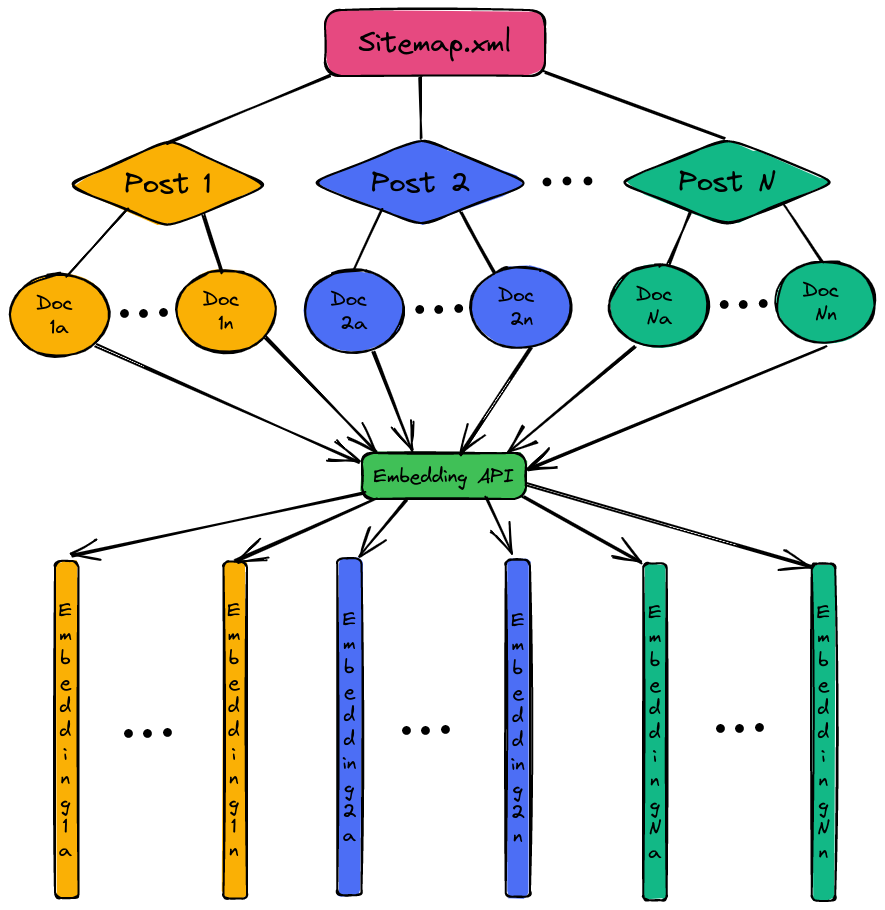
Illustration of the embedding process: each blog post gets split into N documents which each get represented by an embedding vector of 1536 numbers.
Query your website’s URLs
This one is straightforward, because you usually already have a sitemap.xml where you specify the URLs which you use on your website.
I will take my own website as an example, so we consider https://www.paepper.com/sitemap.xml.
Furthermore, I will filter only for the blog posts and will use a method called extract_text_from(url) which we will write later:
import xmltodict
import requests
r = requests.get("https://www.paepper.com/sitemap.xml")
xml = r.text
raw = xmltodict.parse(xml)
pages = []
for info in raw['urlset']['url']:
# info example: {'loc': 'https://www.paepper.com/...', 'lastmod': '2021-12-28'}
url = info['loc']
if 'https://www.paepper.com/blog/posts' in url:
pages.append({'text': extract_text_from(url), 'source': url})
Now we have a pages array with the blog post text and source URL per entry.
Extracting the text only
We still need to write the method extract_text_from(url) which receives the page’s URL and returns the extracted text.
To make it easy, we use BeautifulSoup:
from bs4 import BeautifulSoup
def extract_text_from(url):
html = requests.get(url).text
soup = BeautifulSoup(html, features="html.parser")
text = soup.get_text()
lines = (line.strip() for line in text.splitlines())
return '\n'.join(line for line in lines if line)
It takes only the text, removes trailing white space and drops empty lines.
Split each page’s content into a number of documents
We have all the blog’s data at this point, but due to LLM context limit, we need to make sure that the documents are not too long, so we use the CharacterTextSplitter of langchain to help us out here:
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=1500, separator="\n")
docs, metadatas = [], []
for page in pages:
splits = text_splitter.split_text(page['text'])
docs.extend(splits)
metadatas.extend([{"source": page['source']}] * len(splits))
print(f"Split {page['source']} into {len(splits)} chunks")
Create a vector store of these embeddings
With all these neatly split documents and their source URLs, we can start the embedding process.
This is calling the OpenAI API to get text embeddings for your documents. Each embedding is of size 1536, so that means that each document is represented by a vector of 1536 numbers.
For my blog posts there were around 100k tokens, so the API cost was 0.05€ to embed them:
import faiss
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
import pickle
store = FAISS.from_texts(docs, OpenAIEmbeddings(), metadatas=metadatas)
with open("faiss_store.pkl", "wb") as f:
pickle.dump(store, f)
We stored the resulting embeddings in a FAISS store as faiss_store.pkl.
Asking questions
It’s time for some fun as we can now ask questions about our documents using this qa.py script:
import faiss
from langchain import OpenAI
from langchain.chains import VectorDBQAWithSourcesChain
import pickle
import argparse
parser = argparse.ArgumentParser(description='Paepper.com Q&A')
parser.add_argument('question', type=str, help='Your question for Paepper.com')
args = parser.parse_args()
with open("faiss_store.pkl", "rb") as f:
store = pickle.load(f)
chain = VectorDBQAWithSourcesChain.from_llm(
llm=OpenAI(temperature=0), vectorstore=store)
result = chain({"question": args.question})
print(f"Answer: {result['answer']}")
print(f"Sources: {result['sources']}")
You can call it like this: python qa.py "How to detect objects in images?"
Answer:
Object detection in images can be done using algorithms such as R-CNN, Fast R-CNN, and data augmentation techniques such as shifting, rotations, elastic deformations, and gray value variations.
Sources:
- https://www.paepper.com/blog/posts/deep-learning-on-medical-images-with-u-net/
- https://www.paepper.com/blog/posts/end-to-end-object-detection-with-transformers/
What happens behind the scenes?
How is the answer to our question derived?
The process is as follows:
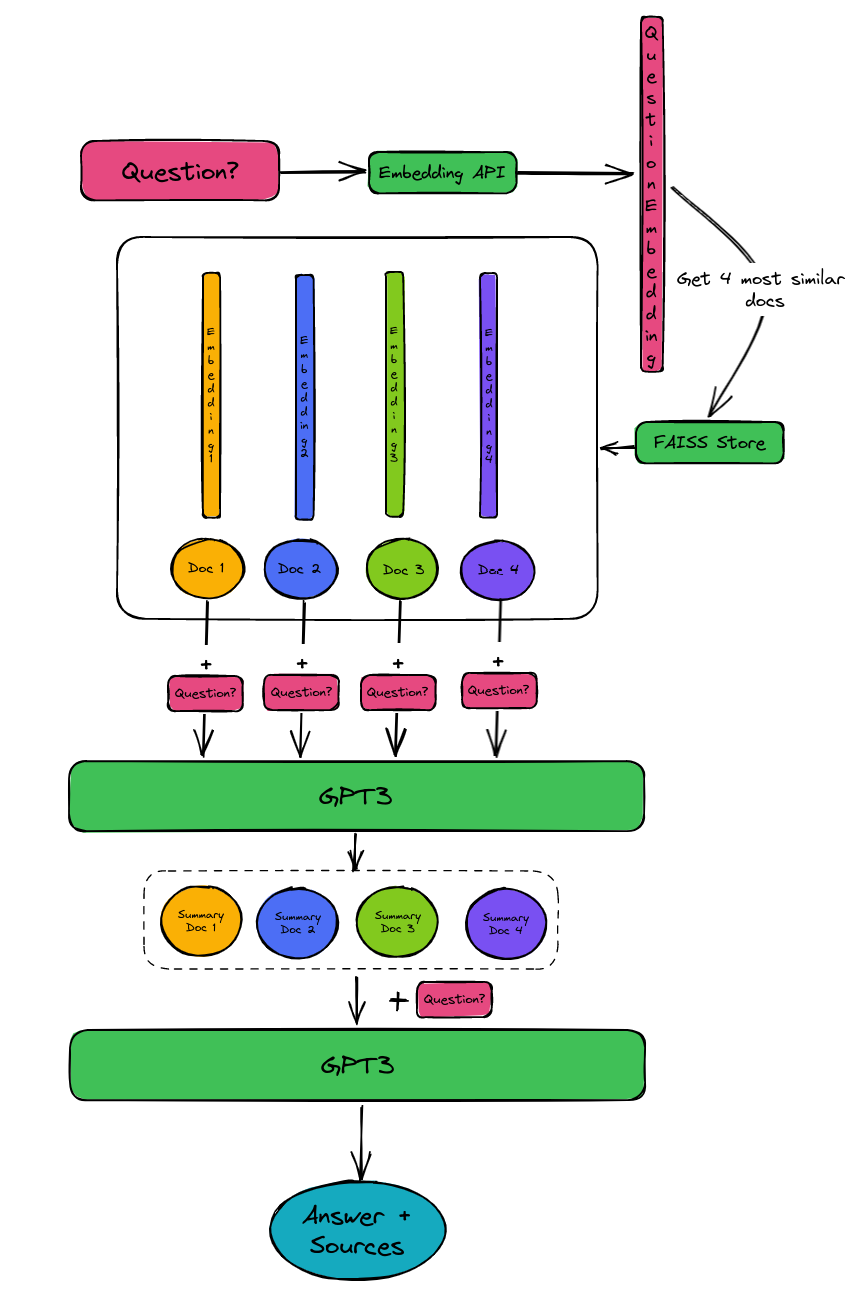
Illustration of the question answering process - see text for details.
- We get the embedding vector of the question
- We query the FAISS store with the question embedding. It searches by embedding similarity and returns the 4 most similar documents (including the source URL of the blog post they originated from).
- We query GPT3 with each of these documents and the question to give us a summary for the document relevant to the query.
- We send all the summaries together with the question to GPT3 for the final answer.
To make GPT3 use the sources, prompt templates are used.
For the overall summary, the combine_prompt_template is used which gives some examples of how to answer a question with several sources.
For the individual document summaries, the question_prompt_template is used which instructs GPT3 to extract the verbatim relevant information relating to the question.