10 minutes
Hyperparameter tuning on numerai data with PyTorch Lightning and weights & biases
To compare the previously described approach of hyperparameter tuning using fastai and wandb, today we’ll see how to tackle the same approach, but using PyTorch Lightning instead of fastai. The goal is to have an automated hyperparameter tuning pipeline running on the Numerai data set.
What is Numerai?
Numerai is a hedge fund which trades stocks in a market neutral fashion. That means that they try to make money without having a lot of risk for their customers. Basically, whenever they buy or call a stock, they sell or short another one to counter-balance the risk.
The fun thing about Numerai is that they take advantage of an ensemble of data science predictions. To do so, they provide you with anonymized features (1050 currently) and a target column. It is a regression problem, so the target is between 0 and 1. You have a training, a validation and a test set. For the training and validation set, the targets are available. For the test set, you only have the features and need to predict the targets.
You then upload your predictions to Numerai (not your model!) and can bet money on the quality of your predictions (in terms of the cryptocurrency Numeraire). If your model turns out to be good, you’ll earn some more money back, but if your predictions were not good, some of your money will be burned / lost. Here, we are not interested in bidding money, but you can also upload your predictions and just see how you do over time.
Setting up PyTorch Lightning and wandb
First, we need to install our dependencies and import the basics from PyTorch Lightning and wandb. Note that I needed to run a slightly older version of PyTorch Lightning when I first did this experiment as there was a bug with running the wandb sweeps. When you are reading this, it’s most likely resolved and you can use the newest version.
!pip install pytorch_lightning==1.4.9 -q # 1.5.2 doesn't work properly with sweeps, see https://github.com/PyTorchLightning/pytorch-lightning/issues/10336
!pip install wandb -q
!pip install einops -q
!pip install numerapi -q
Setting up the data, the model and the optimization process in PyTorch Lightning
First let’s setup the data as a PyTorch Dataset. In contrast to the previous fastai approach, I decided to use two targets: the one we are actually interested in (target) and an auxiliary target which might help the model to find better weights (target_nomi_60). The numerai dataset provides several helper targets that we could use, I just used one additional one here.
Another change compared to the previous blog entry is that I wanted to use the eras (points in time) as my batches. As they are of different sizes, I decided to go about this by letting the dataset return a whole era as one item and use a batch size of 1, so one batch is always one full era. This is because the eras are different points in time, so they might contain separate information, so isolating them seems like a good idea.
import numpy as np
import pandas as pd
from numerapi import NumerAPI
import torch.nn as nn
import torch
from pytorch_lightning import LightningModule, Trainer
from torch.utils.data import Dataset, DataLoader
class NumeraiDataset(Dataset):
def __init__(self, name):
super().__init__()
self.name = name
napi = NumerAPI()
TARGET_AUX = "target_nomi_60"
name = f'numerai_{name}_data.parquet'
self.df = pd.read_parquet(name)
self.df.loc[:, TARGET_AUX].fillna(0.5, inplace=True)
feature_cols = [c for c in self.df if c.startswith("feature_")]
by_eras = self.df.groupby('era')
self.inputs_batched = [
torch.from_numpy(era[1][feature_cols].values) for era in by_eras
]
self.targets_batched = [
torch.from_numpy(era[1]['target'].values) for era in by_eras
]
self.aux_targets_batched = [
torch.from_numpy(era[1][TARGET_AUX].values) for era in by_eras
]
def __len__(self):
return len(self.inputs_batched)
def __getitem__(self, idx):
return self.inputs_batched[idx].float(), self.targets_batched[idx].float(), self.aux_targets_batched[idx].float()
Next, we define the Pytorch LightningModule which contains the neural network. The architecture is mostly the same as the default architecture of the tabular learner in fastai, i.e. a not so deep neural network with fully connected layers and some BatchNorm and Dropout layers for regularization. Naturally, this is a lot more code than in fastai, but you see more explicitly what is being used and I like that especially if you want to experiment a lot and potentially change many details.
class NumeraiModel(LightningModule):
def __init__(self, dropout=0, initial_bn=False, learning_rate=0.003, wd=5e-2):
super().__init__()
layers = []
num_features = [1050, 200, 100]
if initial_bn:
layers.append(nn.BatchNorm1d(num_features[0]))
for i in range(len(num_features) - 1):
layers += [
nn.Linear(num_features[i], num_features[i+1], bias=False),
nn.ReLU(inplace=True),
nn.BatchNorm1d(num_features[i+1])
]
if dropout > 0:
layers.append(nn.Dropout(p=dropout))
layers.append(nn.Linear(num_features[-1], 2))
layers.append(nn.Sigmoid())
self.model = nn.Sequential(*layers)
self.learning_rate = learning_rate
self.wd = wd
self.batch_size = 1
self.loss = nn.MSELoss()
self.save_hyperparameters()
def forward(self, x):
return self.model(x)
def prepare_data(self):
napi = NumerAPI()
current_round = napi.get_current_round(tournament=8) # primary tournament
napi.download_dataset(
"numerai_training_data_int8.parquet", "numerai_training_data.parquet")
napi.download_dataset(
"numerai_validation_data_int8.parquet", "numerai_validation_data.parquet")
def setup(self, stage=None):
if stage == "fit" or stage is None:
self.train_data = NumeraiDataset('training')
self.val_data = NumeraiDataset('validation')
else:
raise Exception('not impl')
def train_dataloader(self):
return DataLoader(self.train_data, batch_size=self.batch_size, num_workers=4)
def val_dataloader(self):
return DataLoader(self.val_data, batch_size=self.batch_size, num_workers=4)
def training_step(self, batch, batch_nb):
inputs, targets, aux_targets = batch
# Era as batch hack, so we need to take out the first fake batch dimension
inputs = inputs[0]
targets = targets[0]
aux_targets = aux_targets[0]
preds = self.model(inputs)
rank_pred = pd.Series(
preds[:, 0].detach().cpu().numpy()).rank(pct=True, method='first')
corr = np.corrcoef(targets.detach().cpu().numpy(), rank_pred)[0,1]
loss = self.loss(preds[:, 0], targets)
loss_aux = self.loss(preds[:, 1], aux_targets)
self.log("train_loss", loss)
self.log("train_loss_aux", loss_aux)
return {'loss': loss + loss_aux, 'corr': corr}
def training_epoch_end(self, outputs):
avg_loss = torch.stack([x['loss'] for x in outputs]).mean()
corrs = [x['corr'] for x in outputs]
mean_corr = np.mean(corrs)
std_corr = np.std(corrs)
sharpe = mean_corr / std_corr
self.log('0_train/loss', avg_loss, on_step=False, on_epoch=True)
self.log('0_train/mean_corr', mean_corr, on_step=False, on_epoch=True)
self.log('0_train/std_corr', std_corr, on_step=False, on_epoch=True)
self.log('0_train/sharpe', sharpe, on_step=False, on_epoch=True)
def validation_step(self, batch, batch_nb):
inputs, targets, _ = batch
inputs = inputs[0]
targets = targets[0]
preds = self.model(inputs)
rank_pred = pd.Series(preds[:,0].cpu()).rank(pct=True, method='first')
corr = np.corrcoef(targets.cpu(), rank_pred)[0,1]
loss = torch.nn.functional.mse_loss(preds[:,0], targets, reduction='mean')
self.log("validation_loss", loss)
return {'loss': loss, 'corr': corr}
def validation_epoch_end(self, outputs):
avg_loss = torch.stack([x['loss'] for x in outputs]).mean()
corrs = [x['corr'] for x in outputs]
mean_corr = np.mean(corrs)
std_corr = np.std(corrs)
sharpe = mean_corr / std_corr
self.log("1_val/loss", avg_loss)
self.log("1_val/mean_corr", mean_corr)
self.log("1_val/std_corr", std_corr)
self.log("1_val/sharpe", sharpe)
return {'val_loss': avg_loss}
def configure_optimizers(self):
return torch.optim.AdamW(
self.model.parameters(), lr=self.learning_rate, weight_decay=self.wd)
Defining the training loop to run for the different sweeps
We have setup our data, the model and our optimization procedure by defining the LightningModule. This is fully self contained and can be used with a Trainer which runs it.
Naturally, this is the approach we’ll take for the train() method which we will use for our wandb hyperparameter optimization sweeps.
PyTorch Lightning always runs a validation epoch after each training epoch and in the validation_epoch_end() step we are already logging all the metrics we are interested in.
So we only need to tell the trainer to use wandb as the logger of choice.
As we want to get our sharpe metric as good as possible for the Numerai competition, we will try to maximize the 1_val/sharpe metric.
The train() method that we define below, will be called by wandb in the sweeps later on to test out the different hyperparameters.
Inside the train() method, we initialize a wandb run using wandb.init() and make sure that wandb has the chance to override the config by using config = wandb.config.
Before and after each run we use the garbage collection and clean the cuda cache just to make sure that no unexpected memory leaks happen between runs.
We then use the seed_everything(42) method from PyTorch Lightning to make the run reproducible. After all, otherwise, the randomization could have a larger effect than our hyperparameters between the runs. This is sth. you should also test and make sure that runs with the same hyperparameters in fact produce the same results.
Then, we initialize the NumeraiModel, the WandbLogger and a ModelCheckpoint (to store the model checkpoint with the highest 1_val/sharpe) and pass all this to the Trainer:
import gc
import random
from pytorch_lightning.loggers import WandbLogger
from pytorch_lightning.callbacks import ModelCheckpoint
from pytorch_lightning.utilities.seed import seed_everything
def train(config=None):
with wandb.init(config=config):
config = wandb.config
gc.collect()
torch.cuda.empty_cache()
try:
seed_everything(seed=42)
numerai_model = NumeraiModel(
dropout=config.dropout,
initial_bn=config.initial_bn,
learning_rate=config.learning_rate,
wd=config.wd)
wandb_logger = WandbLogger(log_model=True)
checkpoint_callback = ModelCheckpoint(monitor="1_val/sharpe", mode="max")
trainer = Trainer(
gpus=1,
max_epochs=config.epochs,
logger=wandb_logger,
callbacks=[checkpoint_callback]
)
trainer.fit(numerai_model)
except Exception as e:
print(e)
del numerai_model
del wandb_logger
del checkpoint_callback
del trainer
gc.collect()
torch.cuda.empty_cache()
Configuring the hyperparameter optimization sweeps
Finally, let’s tell wandb what to optimize for and which hyperparameters to gauge for.
The bayes method can be used to let wandb do baysian optimization for parameter ranges.
We define our 1_val/sharpe as the metric with the goal to maximize it. Specifying a metric is mandatory when running the bayes based optimization.
For the parameters we can either specify a concrete list of values like I did for the number of epochs or a range using min and max like for weight decay (wd).
For the sake of quickly running an example here, I am not using optimal values, but rather a small amount of epochs etc.
import wandb
sweep_config = {
"method": "bayes",
"metric": {
"name": "1_val/sharpe",
"goal": "maximize"
},
"parameters": {
"dropout": {
"min": 0.0,
"max": 0.3
},
"initial_bn": {
"values": [False, True]
},
"epochs": {
"values": [1, 2]
},
"wd": {
"min": 0.01,
"max": 0.1
},
"learning_rate": {
"min": 0.001,
"max": 0.01
}
}
}
sweep_id = wandb.sweep(sweep_config, project='pl-numerai-sweeps-blog')
Create sweep with ID: zxu4ytjx
Sweep URL: https://wandb.ai/mpaepper/pl-numerai-sweeps-blog/sweeps/zxu4ytjx
Let the fun begin
We have created all the configuration and obtained the sweep_id. With this, you can start agents which could run on several machines or like I do here run a single agent in a Jupyter notebook.
An agent needs to know the sweep_id, the function to run (train here) and the number of different runs before finishing.
I chose 10 here for the number of runs as this is just an example. Ideally, you would try out several hundreds to get the optimal combination. You can also omit the count, so the agent will run until you stop it. This is a nice option to start it at night and then stop it in the morning to take a look at the outcome.
wandb.agent(sweep_id, function=train, count=10)
Agent Starting Run: pfhs5bhv with config:
dropout: 0.2302335533911187
epochs: 1
initial_bn: False
learning_rate: 0.008998448222846803
wd: 0.014335789948723535
Waiting for W&B process to finish, PID 3333… (success).
Run history:
| 0_train/loss | ▁ |
| 0_train/mean_corr | ▁ |
| 0_train/sharpe | ▁ |
| 0_train/std_corr | ▁ |
| 1_val/loss | ▁ |
| 1_val/mean_corr | ▁ |
| 1_val/sharpe | ▁ |
| 1_val/std_corr | ▁ |
| epoch | ▁▁▁▁▁▁▁▁▁▁▁▁▁ |
| train_loss | ▅▄▄▅█▃▅▁▃▃▆ |
| train_loss_aux | ▇█▄▅▆▁▄▃▅▅█ |
| trainer/global_step | ▁▂▂▃▄▄▅▆▆▇███ |
| validation_loss | ▁ |
Run summary:
| 0_train/loss | 0.10003 |
| 0_train/mean_corr | 0.04312 |
| 0_train/sharpe | 1.76145 |
| 0_train/std_corr | 0.02448 |
| 1_val/loss | 0.05012 |
| 1_val/mean_corr | 0.012 |
| 1_val/sharpe | 0.38144 |
| 1_val/std_corr | 0.03146 |
| epoch | 0 |
| train_loss | 0.05016 |
| train_loss_aux | 0.04981 |
| trainer/global_step | 573 |
| validation_loss | 0.05012 |
… and potentially many more similar outputs for the different runs.
Evalutating the results in weights and biases
Let’s take a look again at the feature importance table which you can generate from the sweeps in wandb:
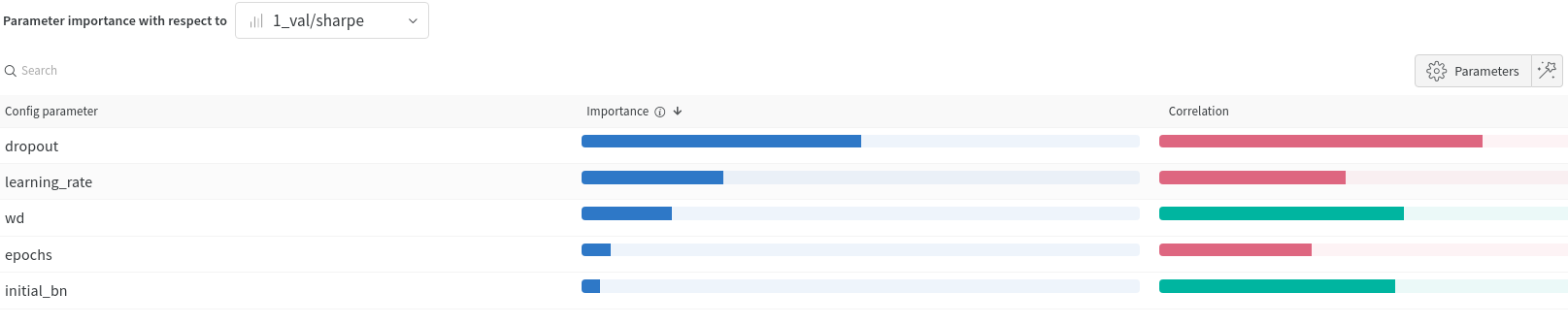
Feature importance weight table from wandb
As we can see, there is positive correlation to our 1_val/sharpe metric for weight decay and having an initial batch norm layer.
In contrast, dropout, learning rate and the number of epochs is negatively correlated, so smaller values seemed better.
To gain further insights, let’s use the parallel coordinates plot to see the summary of our 10 runs:
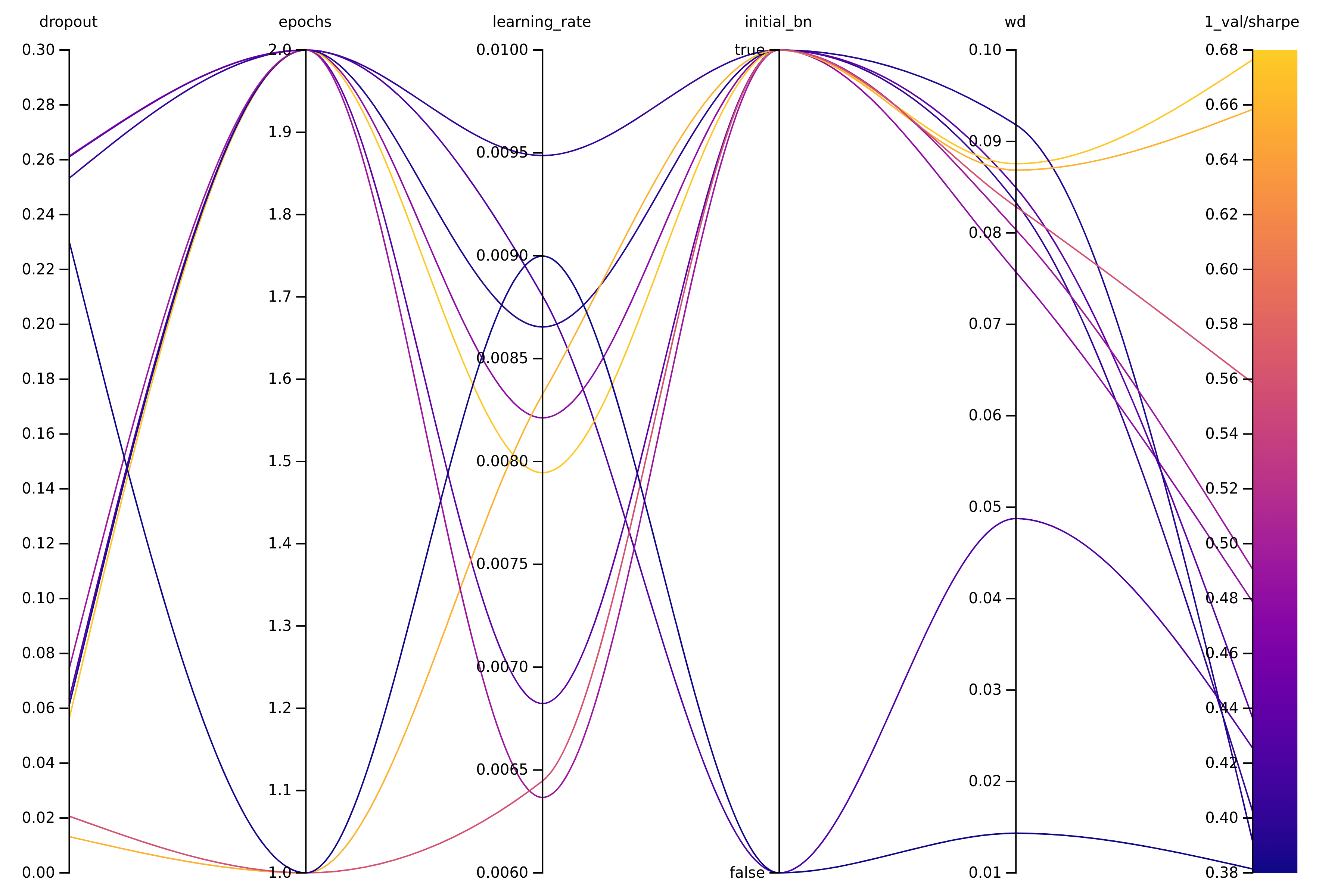
Parallel coordinates plot from wandb
The run which finished with the highest val_sharpe value (yellow line) indeed used only a small amount of dropout, but higher values for the weight decay, so weight decay might be the better choice for regularization here. It also used the initial batch norm layer. However, here it used 2 epochs which seemed to work out, but again the number of runs and hyperparameter settings are too little to make real conclusions, this is only for illustration.
Summary wandb with PyTorch Lightning
Compared to the fastai approach, with PyTorch Lightning you need to figure out a few more details and write a bit more code. This is good and bad at the same time. I like having things explicit, so with PyTorch Lightning I see the whole picture how my model is trained whereas with fastai it’s more of a blackbox (until you look inside). In contrast, it’s definitely faster to get something running and have reasonable defaults with fastai. Overall, I’d say that for getting quick first experiments or a baseline, fastai is perfect. If you need to change a lot of the underlying details, for me it’s easier to write them out yourself rather than figuring out how to change all the internals of fastai.
python pytorch machinelearning deeplearning hyperparameters lightning wandb
Machine Learning Deep Learning
1996 Words
December 05, 2021